第4章 数据清洗
4.1 查看数据信息
导入数据后应该了解字段信息,字段的数据类型,哪些字段有缺失值
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['Simhei']; #SimHei黑体
plt.rcParams['axes.unicode_minus']=False; #正常显示图中负号
data = pd.read_csv("data/数据/学生.csv")
data.head(5).pipe(lambda df:print(df.to_markdown(tablefmt="github")))| 姓名 | 性别 | 班级 | 数学 | 语文 | 英语 | |
|---|---|---|---|---|---|---|
| 0 | a1 | 男 | 高一(1)班 | 61 | 59 | 70 |
| 1 | a2 | 女 | 高一(2)班 | 62 | 77 | 74 |
| 2 | a3 | 女 | 高一(3)班 | 58 | 71 | 83 |
| 3 | a4 | 男 | 高一(4)班 | 65 | 57 | 71 |
| 4 | a5 | 男 | 高一(5)班 | 56 | 83 | 72 |
4.1.1 .info()
查看字段名,缺失值和字段类型
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1800 entries, 0 to 1799
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 姓名 1800 non-null object
1 性别 1800 non-null object
2 班级 1800 non-null object
3 数学 1800 non-null int64
4 语文 1800 non-null int64
5 英语 1800 non-null int64
dtypes: int64(3), object(3)
memory usage: 84.5+ KB4.1.3 .describe()
`.describe(include/exclude=[])
默认只对数值类型进行各种字段的描述,可以设置include和exclude参数对类型进行选择
| 数学 | 语文 | 英语 | |
|---|---|---|---|
| count | 1800 | 1800 | 1800 |
| mean | 64.3439 | 69.145 | 74.5239 |
| std | 5.92552 | 6.96314 | 4.88335 |
| min | 44 | 47 | 60 |
| 25% | 60 | 65 | 71 |
| 50% | 64 | 69 | 75 |
| 75% | 68 | 74 | 78 |
| max | 87 | 94 | 90 |
| 姓名 | 性别 | 班级 | |
|---|---|---|---|
| count | 1800 | 1800 | 1800 |
| unique | 1800 | 2 | 60 |
| top | a1 | 男 | 高一(1)班 |
| freq | 1 | 918 | 30 |
4.2 缺失值

4.2.1 查看缺失值
.isnull(axis),.notnull(axis)
数据缺失,python的None对象,numpy中的np.nan都被视为缺失,空字符串不被视为缺失。
nadata = pd.DataFrame({'null':[None,np.nan,'','nan',0]*2,
'value':np.random.choice([None,np.nan]+list(range(10)),10,)})
nadata.head() null value
0 None 1
1 NaN 4
2 7
3 nan 0
4 0 0 null value
0 True False
1 True False
2 False False
3 False False
4 False False null value
2 7
3 nan 0
4 0 0
7 4
8 nan None
9 0 3null 0.4
value 0.1
dtype: float64lack_rate = 0.3
#选取出所有缺失比例大于0.3的字段名
(nadata.isnull().sum()/len(nadata)).pipe(lambda df:df[df>lack_rate].index.values)array(['null'], dtype=object)通常对于缺失值的处理,最常用的方法无外乎删除法、替换法和插补法。删除法是指将缺失值所在的观测行删除(前提是缺失行的比例非常低,如5%以内),或者删除缺失值所对应的变量(前提是该变量中包含的缺失值比例非常高,如70%左右);替换法是指直接利用缺失变量的均值、中位数或众数替换该变量中的缺失值,其好处是缺失值的处理速度快,弊端是易产生有偏估计,导致缺失值替换的准确性下降;插补法则是利用有监督的机器学习方法(如回归模型、树模型、网络模型等)对缺失值作预测,其优势在于预测的准确性高,缺点是需要大量的计算,导致缺失值的处理速度大打折扣。
4.2.2 删除缺失值
.dropna(axis,how,subset,thresh)
null value
0 None 1
1 NaN 4
2 7
3 nan 0
4 0 0
5 None 8
6 NaN 9
7 4
8 nan None
9 0 3 null value
2 7
3 nan 0
4 0 0
7 4
8 nan None
9 0 3 null value
0 None 1
1 NaN 4
2 7
3 nan 0
4 0 0
5 None 8
6 NaN 9
7 4
8 nan None
9 0 34.2.3 填补缺失值
.fillna(value,method,**kwargs)
通过给字段传递标量,可以进行均值,最大值,最小值,中值等填补,通过method参数可以进行前向和后向填补。
null value
0 0 1
1 0 4
2 7
3 nan 0
4 0 0
5 0 8
6 0 9
7 4
8 nan 0
9 0 3 null value
0 0 1
1 0 4
2 7
3 nan 0
4 0 0
5 0 8
6 0 9
7 4
8 nan 4
9 0 3<string>:1: FutureWarning: DataFrame.fillna with 'method' is deprecated and will raise in a future version. Use obj.ffill() or obj.bfill() instead.
null value
0 1
1 4
2 7
3 nan 0
4 0 0
5 8
6 9
7 4
8 nan 3
9 0 34.3 类型转换
读入的数据类型包含object(任何对象都可以用object来存储),number(数值类型),string(字符串类型),bool(逻辑类型).
可以用.select_dtypes(include/exclude=[])选取对应类型的列
姓名 性别 班级
0 a1 男 高一(1)班
1 a2 女 高一(2)班
2 a3 女 高一(3)班
3 a4 男 高一(4)班
4 a5 男 高一(5)班
... ... .. ...
1795 a1796 男 高三(16)班
1796 a1797 男 高三(17)班
1797 a1798 女 高三(18)班
1798 a1799 女 高三(19)班
1799 a1800 女 高三(20)班
[1800 rows x 3 columns] 数学 语文 英语
0 61 59 70
1 62 77 74
2 58 71 83
3 65 57 71
4 56 83 72
... .. .. ..
1795 65 73 71
1796 68 66 75
1797 50 65 72
1798 64 73 70
1799 60 81 65
[1800 rows x 3 columns]字符串和日期在刚读入时都是object类型,需要转换为字符串类型,日期类型才能进行.str和.dt操作,各类型转换转化方法见下表.
| 方法 | 作用 |
|---|---|
| df.astype() | string,object,int32,int64,datetime64,boolean等 |
| pd.to_numeric() | 转化成数值类型 |
| pd.to_datetime() | 转化成时间格式,datetime64 |
| int,float,bool,str | 只对标量操作 |
字符串类型的浮点数必须先转为浮点数才能转为int
姓名 object
性别 object
班级 object
数学 int64
语文 int64
英语 int64
dtype: objectts = pd.read_csv("data/数据/year-month-day.csv",index_col=[0]).reset_index().rename(columns={"index":"day"})
ts.dtypesday object
value float64
dtype: object姓名 string[python]
性别 string[python]
班级 string[python]
数学 int64
语文 int64
英语 int64
dtype: objectday datetime64[ns]
value float64
dtype: object0 2023
1 2023
2 2023
3 2023
4 2023
Name: day, dtype: int324.4 重复值
数据的记录是否存在重复值,重复值有无存在意义
4.4.1 查看重复值
.duplicated(subset),可以设置subset参数只对某些子集判断
FalseEmpty DataFrame
Columns: [姓名, 性别, 班级, 数学, 语文, 英语]
Index: []04.4.2 删除重复值
.drop_duplicates(subset),同样可以设置subset参数
姓名 性别 班级 数学 语文 英语
0 a1 男 高一(1)班 61 59 70
1 a2 女 高一(2)班 62 77 74
2 a3 女 高一(3)班 58 71 83
3 a4 男 高一(4)班 65 57 71
4 a5 男 高一(5)班 56 83 72
... ... .. ... .. .. ..
1795 a1796 男 高三(16)班 65 73 71
1796 a1797 男 高三(17)班 68 66 75
1797 a1798 女 高三(18)班 50 65 72
1798 a1799 女 高三(19)班 64 73 70
1799 a1800 女 高三(20)班 60 81 65
[1800 rows x 6 columns] 姓名 性别 班级 数学 语文 英语
0 a1 男 高一(1)班 61 59 70
1 a2 女 高一(2)班 62 77 74
2 a3 女 高一(3)班 58 71 83
3 a4 男 高一(4)班 65 57 71
4 a5 男 高一(5)班 56 83 72
... ... .. ... .. .. ..
1795 a1796 男 高三(16)班 65 73 71
1796 a1797 男 高三(17)班 68 66 75
1797 a1798 女 高三(18)班 50 65 72
1798 a1799 女 高三(19)班 64 73 70
1799 a1800 女 高三(20)班 60 81 65
[1800 rows x 6 columns]4.5 异常值
异常值也称为离群点,就是那些远离绝大多数样本点的特殊群体,通常这样的数据点在数据集中都表现出不合理的特性。如果忽视这些异常值,在某些建模场景下就会导致结论的错误(如线性回归模型、K均值聚类等),所以在数据的探索过程中,有必要识别出这些异常值并处理好它们。
对于异常的判断和处理要根据实际情况进行相应的判断和处理.
4.5.1 查看异常值
通常,异常值的识别可以借助于图形法(如箱线图、正态分布图)和建模法(如线性回归、聚类算法、K近邻算法)
4.5.1.1 箱线图
箱线图技术实际上就是利用数据的分位数识别其中的异常点,该图形属于典型的统计图形,在学术界和工业界都得到广泛的应用。箱线图的形状特征如下图所示:
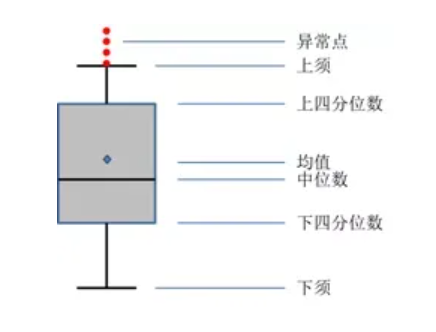
图中的下四分位数指的是数据的25%分位点所对应的值(Q1);中位数即为数据的50%分位点所对应的值(Q2);上四分位数则为数据的75%分位点所对应的值(Q3);上须的计算公式为Q3+1.5(Q3-Q1);下须的计算公式为Q1-1.5(Q3-Q1)。其中,Q3-Q1表示四分位差。如果采用箱线图识别异常值,其判断标准是,当变量的数据值大于箱线图的上须或者小于箱线图的下须时,就可以认为这样的数据点为异常点。
所以,基于上方的箱线图,可以定义某个数值型变量中的异常点和极端异常点,它们的判断表达式如下表所示:

abdata = pd.DataFrame({'value':list(np.random.normal(70,5,100))+[50,57,83,90]})
abdata.boxplot(
whis = 1.5, # 指定1.5倍的四分位差
widths = 0.7, # 指定箱线图的宽度为0.8
patch_artist = True, # 指定需要填充箱体颜色
showmeans = True, # 指定需要显示均值
#boxprops = {'facecolor':'steelblue'}, # 指定箱体的填充色为铁蓝色
# 指定异常点的填充色、边框色和大小
#flierprops = {'markerfacecolor':'red', 'markeredgecolor':'red', 'markersize':4}, # 指定均值点的标记符号(菱形)、填充色和大小
#meanprops = {'marker':'D','markerfacecolor':'black', 'markersize':4},
#medianprops = {'linestyle':'--','color':'orange'},#指定中位数的标记符号(虚线)和颜色
#labels = [''] # 去除箱线图的x轴刻度值
)
#显示图形
plt.show()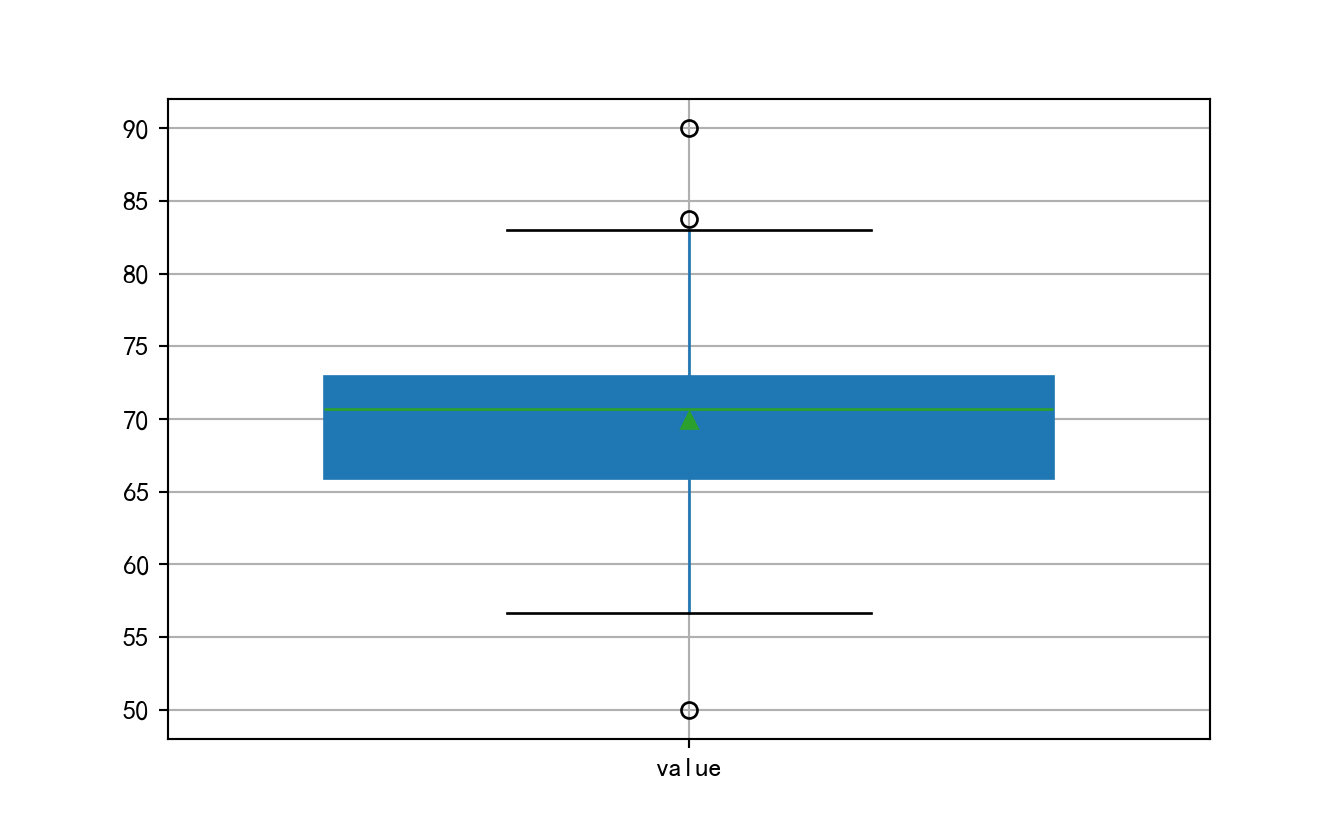
这样做只能直观呈现,要想得到异常点,可以手动计算选择
q1,q3 = abdata.value.quantile(q=[0.25,0.75])
abdata[(abdata.value < q1-1.5*(q3-q1)) | (abdata.value>q3+1.5*(q3-q1))] value
99 83.752253
100 50.000000
103 90.0000004.5.1.2 正态分布图
如果数据满足正态分布,还可以通过3\(\sigma\)的准则来进行异常值的判断,根据正态分布的定义可知,数据点落在偏离均值正负1倍标准差(即sigma值)内的概率为68.2%;数据点落在偏离均值正负2倍标准差内的概率为95.4%;数据点落在偏离均值正负3倍标准差内的概率为99.6%。
所以,换个角度思考上文提到的概率值,如果数据点落在偏离均值正负2倍标准差之外的概率就不足5%,它属于小概率事件,即认为这样的数据点为异常点。同理,如果数据点落在偏离均值正负3倍标准差之外的概率将会更小,可以认为这些数据点为极端异常点。为使读者直观地理解文中提到的概率值,可以查看标准正态分布的概率密度图,如下图所示:
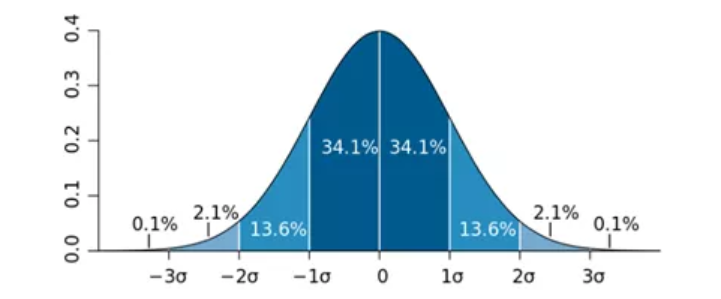
可以按照下表中的判断条件,识别出数值型变量的异常点和极端异常点,如下表所示:

# 绘制单条折线图,并在折线图的基础上添加点图
abdata.index = pd.date_range("2023-01-01",periods=len(abdata))
abdata.plot(
linestyle = '-', # 设置折线类型
linewidth = 2, # 设置线条宽度
color = 'steelblue', # 设置折线颜色
marker = 'o', # 往折线图中添加圆点
markersize = 4, # 设置点的大小
markeredgecolor='black', # 设置点的边框色
markerfacecolor='black') # 设置点的填充色
# 添加上下界的水平参考线(便于判断异常点,如下判断极端异常点,只需将2改为3)
plt.axhline(y = abdata.value.mean() - 2*abdata.value.std(), linestyle = '--', color = 'gray')
plt.axhline(y = abdata.value.mean() + 2*abdata.value.std(), linestyle = '--', color = 'gray')
# 导入模块,用于日期刻度的修改(因为默认格式下的日期刻度标签并不是很友好)
import matplotlib as mpl
# 获取图的坐标信息
ax = plt.gca()
# 设置日期的显示格式
date_format = mpl.dates.DateFormatter("%m-%d")
ax.xaxis.set_major_formatter(date_format)
# 设置x轴每个刻度的间隔天数
xlocator = mpl.ticker.MultipleLocator(7)
ax.xaxis.set_major_locator(xlocator)
# 为了避免x轴刻度标签的紧凑,将刻度标签旋转45度
plt.xticks(rotation=45)(array([19355., 19362., 19369., 19376., 19383., 19390., 19397., 19404.,
19411., 19418., 19425., 19432., 19439., 19446., 19453., 19460.,
19467.]), [Text(19355.0, 0, '12-29'), Text(19362.0, 0, '01-05'), Text(19369.0, 0, '01-12'), Text(19376.0, 0, '01-19'), Text(19383.0, 0, '01-26'), Text(19390.0, 0, '02-02'), Text(19397.0, 0, '02-09'), Text(19404.0, 0, '02-16'), Text(19411.0, 0, '02-23'), Text(19418.0, 0, '03-02'), Text(19425.0, 0, '03-09'), Text(19432.0, 0, '03-16'), Text(19439.0, 0, '03-23'), Text(19446.0, 0, '03-30'), Text(19453.0, 0, '04-06'), Text(19460.0, 0, '04-13'), Text(19467.0, 0, '04-20')])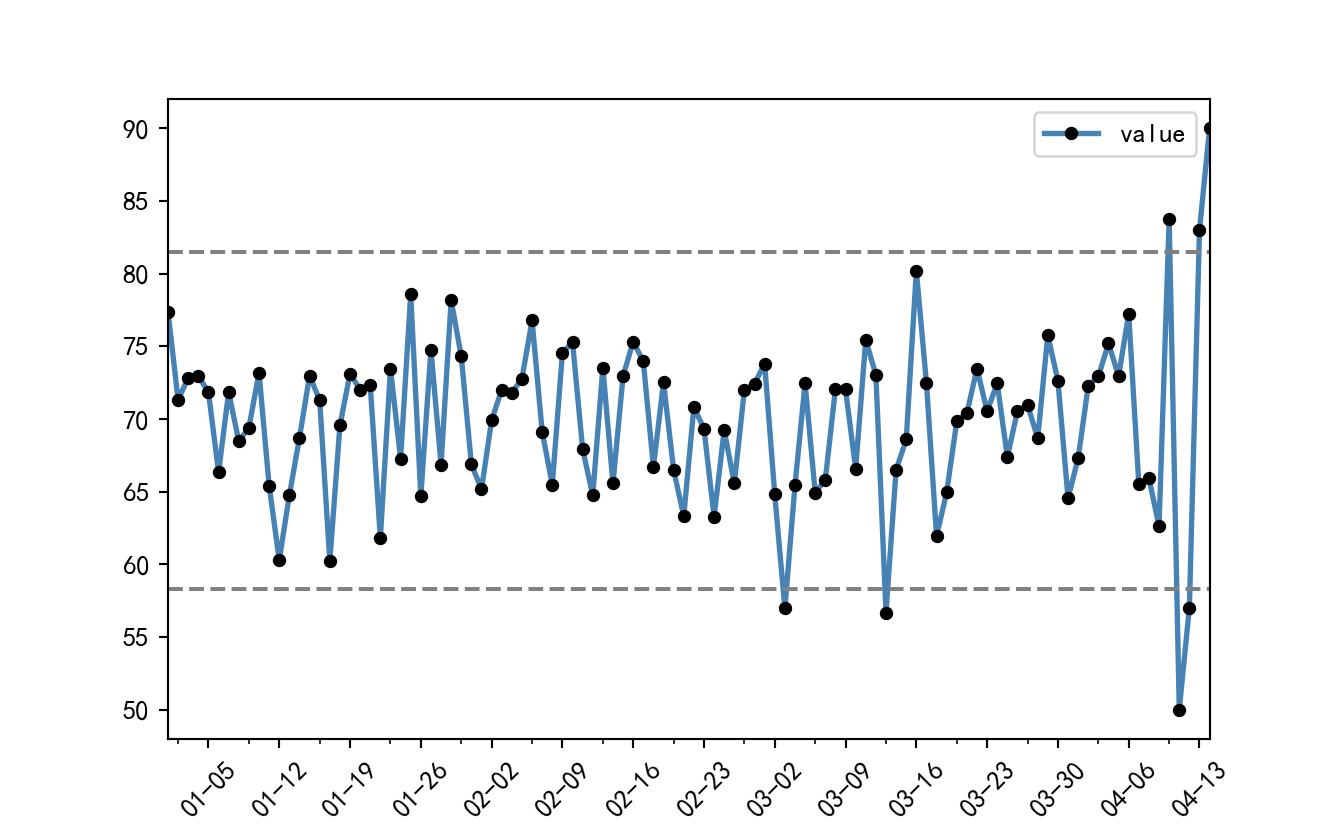
4.6 字段值的处理
4.6.1 .map()
.map(func/**kwargs)
处理一个字段中每一类元素(如果有类未被指定会被map为np.nan)或每一个元素
序列带有.map()方法,数据框没有,所以可以对单个字段进行map操作,若想同时对多个字段进行map操作,可以结合agg函数。
可以传递函数或字典
0 male
1 NaN
2 NaN
3 male
4 male
Name: 性别, dtype: object4.6.2 .replace()
.replace(to_repalce,value,method)
对特定的几个值进行替换
0 replace
1 replace
2
3 nan
4 0
5 replace
6 replace
7
8 nan
9 0
Name: null, dtype: object可以只对某一列的某一类值进行替换,其他种类不变
null value
0 None 1
1 NaN 4
2 7
3 nan 0
4 00 0
5 None 8
6 NaN 9
7 4
8 nan None
9 00 34.6.3 .str
对string类型的字段中的元素进行string类型的操作
- 字符串列表的默认类型是object,我们如果想指定类型,可以在生成Series时声明dtype,或者之后使用.astype()方法
- dtype = “string”/pd.StringDtype()
- .astype(“string”)
- NA 将会被转化为< NA >
- method
- .str.lower(),.str.upper():小写,大写
- .str.len():字符串长度
- .str.strip():清除两边空格
- .str.split(),.str.rsplit():切分字符串
- .str.get(1)=.str[1],可以获得split后的每个element的id为1的元素
- .expand =True:自动把每个切分值作为一列
- n=1:切分一次后就不切分
- .str.replace(pat,repl):可以使用正则表达式
- regex:是否使用正则表达式,设置为False时,pat,repl必须是字符串
- case:是否区分大小写
- pat:可以是re.compile对象,比如
re.compile(r"^.a|dog", flags=re.IGNORECASE) - repl:可以是函数,函数的参数是一个正则表达式对象,比如match对象
- .str.cat(sep=““,others=):concatenate,把每个元素以sep为分隔结合到一起
- sep:默认是空
- na_rep:默认空值是不被concatenate,可以为空值设置一个字符串用来连接
- others:
- Concatenating a Series and something array-like into a Series:row的数目相同
- Concatenating a Series and an indexed object into a Series, with alignment:可以指定join参数
- Concatenating a Series and many objects into a Series:Several array-like items (specifically: Series, Index, and 1-dimensional variants of np.ndarray) can be combined in a list-like container (including iterators, dict-views, etc.).
- .str.extract():returns only the first match
- 接受一个正则表达式:至少有一个group,然后一个group为一列,每个字符若无匹配项则为< NA >
- .str.extractall():Extract all matches in each subject ,结果通常是一个有着MultiIndex的DataFrame,最后一层level一般是“match”,代表了subject的顺序
- str.contains(pattern):测试字符串是否包含一个模式
- str.match(pattern):测试字符串是否匹配一个模式,从字符串开头匹配
- str.fullmatch(pattern):测试整个字符串是否满足模式
- str.get_dummies():
- Series:pd.Series([“a”,“a|b”,np.nan,“a|c”]).str.get_dummies(sep=“|”),返回DataFrame,相当于每个元素是一些特征的集合,我们找到所有的集合作为column,然后赋予0,1
- Index:MultiIndex
|
Method |
Description |
|---|---|
|
Concatenate strings |
|
|
Split strings on delimiter |
|
|
Split strings on delimiter working from the end of the string |
|
|
Index into each element (retrieve i-th element) |
|
|
Join strings in each element of the Series with passed separator |
|
|
Split strings on the delimiter returning DataFrame of dummy variables |
|
|
Return boolean array if each string contains pattern/regex |
|
|
Replace occurrences of pattern/regex/string with some other string or the return value of a callable given the occurrence |
|
|
Duplicate values ( |
|
|
Add whitespace to left, right, or both sides of strings |
|
|
Equivalent to |
|
|
Equivalent to |
|
|
Equivalent to |
|
|
Equivalent to |
|
|
Split long strings into lines with length less than a given width |
|
|
Slice each string in the Series |
|
|
Replace slice in each string with passed value |
|
|
Count occurrences of pattern |
|
|
Equivalent to |
|
|
Equivalent to |
|
|
Compute list of all occurrences of pattern/regex for each string |
|
|
Call |
|
|
Call |
|
|
Call |
|
|
Compute string lengths |
|
|
Equivalent to |
|
|
Equivalent to |
|
|
Equivalent to |
|
|
Equivalent to |
|
|
Equivalent to |
|
|
Equivalent to |
|
|
Equivalent to |
|
|
Equivalent to |
|
|
Equivalent to |
|
|
Equivalent to |
|
|
Equivalent to |
|
|
Equivalent to |
|
|
Equivalent to |
|
|
Equivalent to |
|
|
Return Unicode normal form. Equivalent to |
|
|
Equivalent to |
|
|
Equivalent to |
|
|
Equivalent to |
|
|
Equivalent to |
|
|
Equivalent to |
|
|
Equivalent to |
|
|
Equivalent to |
|
|
Equivalent to |
|
|
Equivalent to |
|
|
Equivalent to |